【6月16日】北京时间6月11-14日,计算机视觉顶会CVPR 2025在美国田纳西州纳什维尔举行,小鹏汽车受邀参与自动驾驶研讨会CVPR WAD(Workshop on Autonomous Driving),与Waymo、英伟达、加利福尼亚大学洛杉矶分校(UCLA)、图宾根大学(University of Tuebingen)等来自工业界和学术界的自动驾驶同行共同探讨业界最新AI技术。

AI大模型浪潮以来,自动驾驶领域发生了技术范式的切换,已经从过去人类手写规则的模型,升级为基于海量数据训练出的AI模型,相关技术进展也成了这几年CVPR的大热议题。在本届的CVPR WAD上,小鹏世界基座模型负责人刘先明博士发表了题为《通过大规模基础模型实现自动驾驶的规模化》(Scaling up Autonomous Driving via Large Foudation Models)的演讲,系统地介绍了小鹏汽车自研的业界首个超大规模自动驾驶基座模型的历程和方法,披露了其在模型预训练、强化学习、模型车端部署、AI和数据基础设施搭建方面的前沿探索,为同行带去工业领域的实践经验。

同一天,在大洋此岸的中国广州,小鹏汽车宣布推出全球首款搭载L3级算力平台的AI汽车——小鹏G7,并且行业首次提出了「L3级算力平台」的两大标准:第一,“有效算力”大于2000TOPS;第二,搭载本地部署的「VLA+VLM模型」。小鹏汽车认为,「大算力+物理世界大模型+大数据」将共同定义未来“AI汽车”的能力上限,其中的“物理世界大模型”正是刘博士带队研发的小鹏世界基座模型。
今年4月,小鹏汽车已对外宣布正在研发参数规模达到720亿的云端大模型,即“小鹏世界基座模型”。该基座模型是以大语言模型为骨干网络,使用海量优质驾驶数据训练的VLA大模型(视觉-语言-行为大模型),具备视觉理解能力、链式推理能力(CoT)和动作生成能力。
如果说传统的自动驾驶模型是负责驾驶的“小脑”,那么基于大语言模型和海量高质量数据训练的自动驾驶基座模型,无疑是同时具备驾驶能力和思考能力的“大脑”。它能让汽车像人类一样,主动思考和理解世界,丝滑地处理训练数据中没有见过的长尾场景,而不只是机械地执行人类写好的规则代码。从“小脑”到“大脑”的飞跃,是自动驾驶技术的质变,能让汽车完成从L2辅助驾驶到L4自动驾驶的纵向技术迭代,最终抵达真正的无人驾驶。
刘博士表示,小鹏汽车在云上训练了10亿、30亿、70亿、720亿等多个参数的模型,并且持续向模型“投喂”更大规模的训练数据。目前,小鹏世界基座模型累计“吃下”2000多万条视频片段(每条时长30秒)。在这一过程中,研发团队清晰地看到了规模法则(Scaling Law)的显现。也就是说,模型的参数量越大、模型学习的数据越多,模型的性能越强。这是AI大模型浪潮以来,行业内首次明确验证规模法则在自动驾驶VLA模型上持续生效。
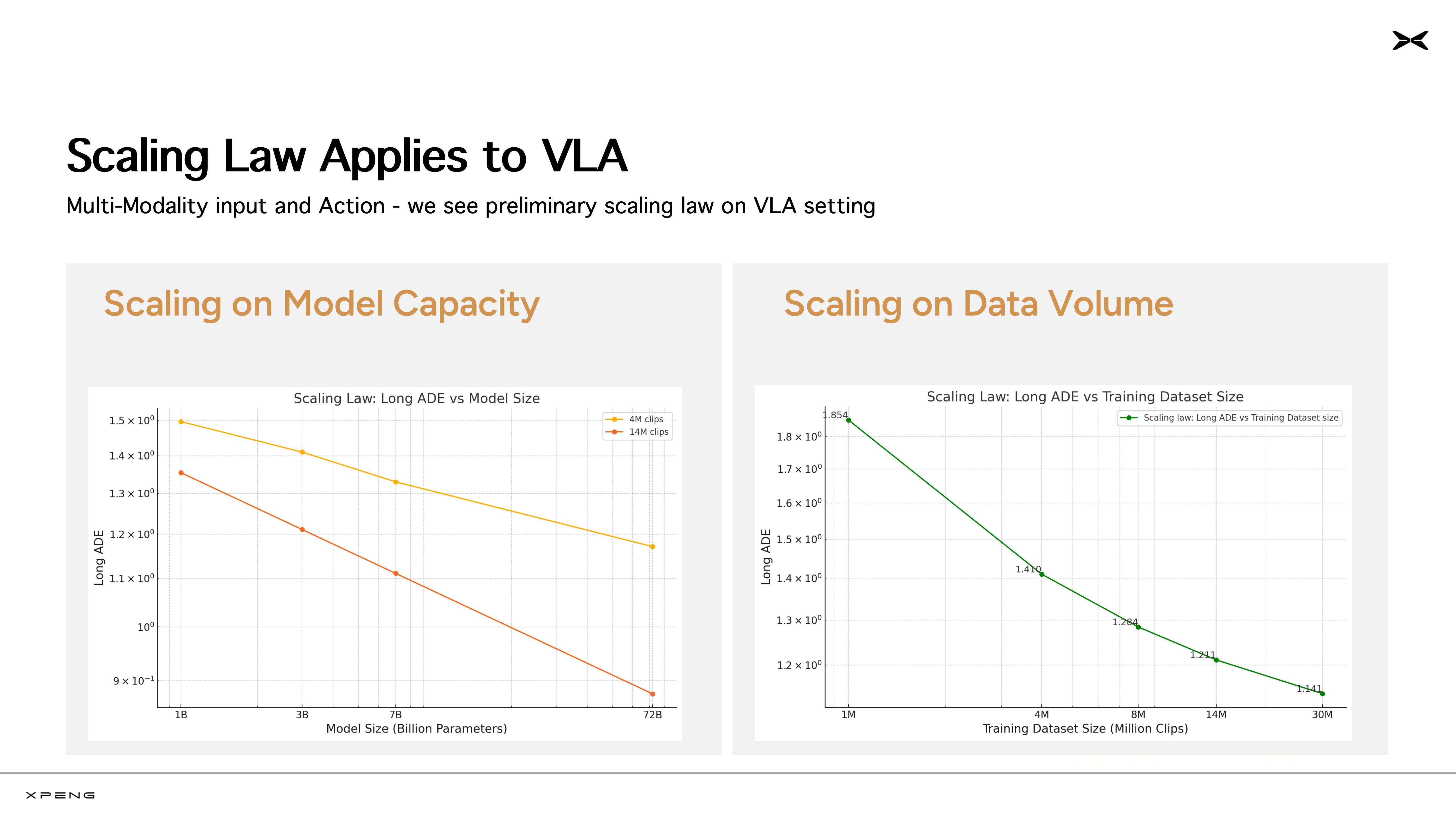
由于车端算力限制,最终能够部署上车的模型,参数规模通常都比较小。目前,业界主流的车端模型参数一般在几百万到十亿级别。如果在车端直接训练小模型,规模法则没有发挥空间,模型的性能上限也会受限,更无从实现强大的CoT等能力。基于这一判断,小鹏汽车早在去年就确定了云端基模技术路线,也即在云端“不计成本”地训练超大规模世界基座模型,再通过蒸馏的方式生产出适配车端算力的小模型。蒸馏能够最大限度地保留云端基模的核心能力,帮助车端模型跳出车端算力的“一亩三分地”。
在规则时代,自动驾驶模型属于“模仿学习”模型,只能处理训练数据中见过的场景。而自动驾驶核心难点在于处理那些罕见的、复杂的、事关安全的长尾问题,但是这些问题发生概率极低,因此往往没有足够的数据供模型学习。到了AI时代,全新的解法已然出现,“强化学习”成为了提升模型思考能力、帮助模型处理长尾场景的重要手段。小鹏汽车证实了“云端基座模型+强化学习”的组合,是让模型性能突破天际的最好方法。云端基座模型可以类比为人类的“天资”,而强化学习就像能力激化器,用来激发云端基座模型的智力潜能,提高基模的泛化能力。
与学术研究不同,整车厂的模型研发工作最终都要在真实的物理世界完成验证。目前,小鹏汽车就已经在后装算力的车端上用小尺寸的基座模型实现了控车。在没有任何规则代码托底的情况下,新的“AI大脑”展现出令人惊喜的基础驾车技能,能够丝滑地加减速、变道绕行、转弯掉头、等待红绿灯等等。
小鹏世界基座模型并不是静态的,它在持续学习、循环进化(Continued Online Learning)。可以将模型的迭代过程分成内、外两个循环,内循环是指包含预训练、后训练(包括监督精调SFT和强化学习RL)和蒸馏部署的模型训练过程;外循环,是指模型在车端部署之后,持续获取新的驾驶数据和用户反馈,继续用于云端基模的训练。
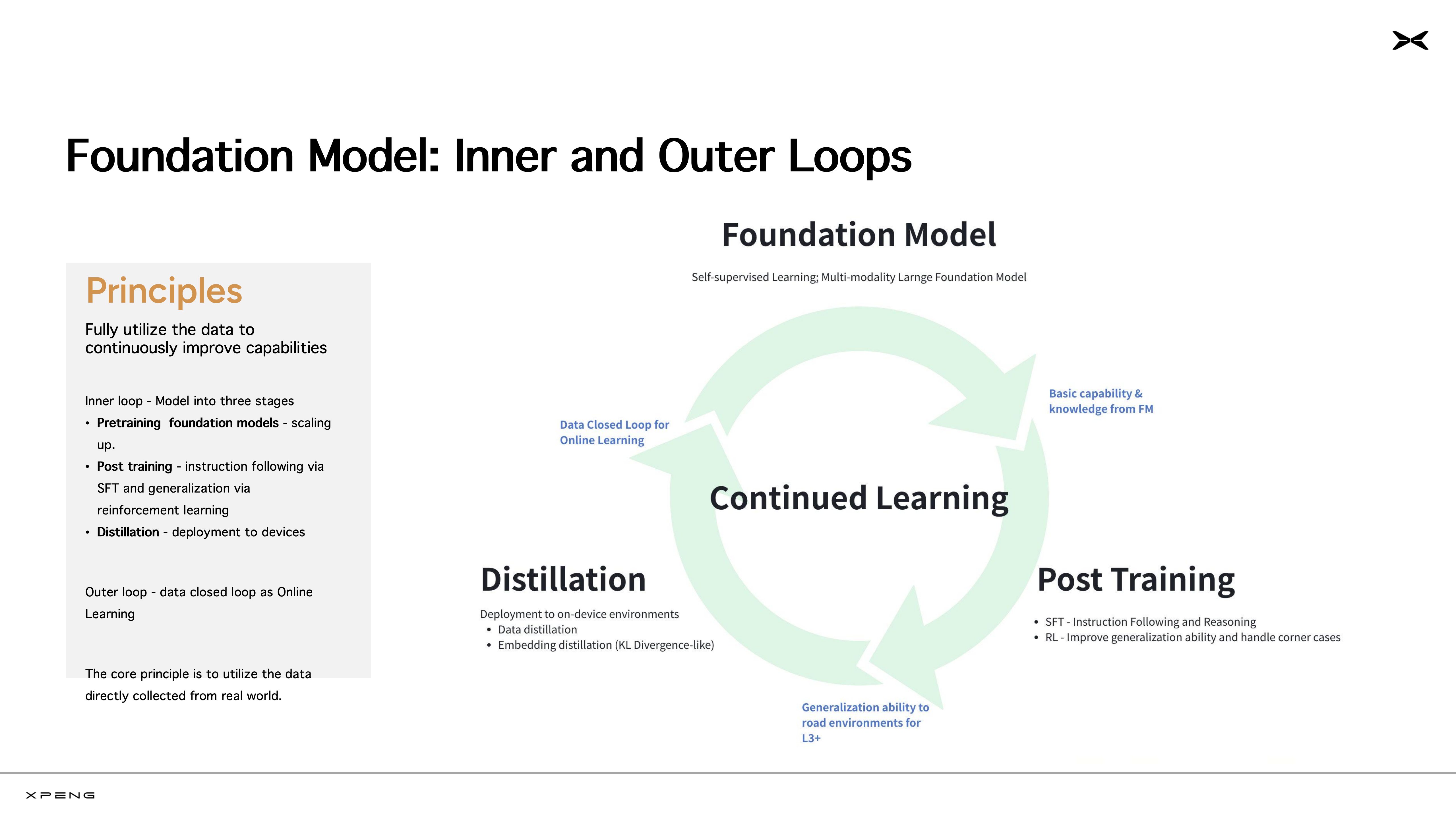
值得关注的是,在此次CVPR WAD上,刘博士所提出的“软件3.0时代,打造云端工厂,开启AI时代模型生产新范式”同样让现场参会者留下了深刻的印象。事实上,为了研发世界基座模型,小鹏汽车从去年便开始布局AI基础设施,建成了国内汽车行业首个万卡智算集群,用以支持基座模型的预训练、后训练、模型蒸馏、车端模型训练等任务。小鹏汽车将这套从云到端的生产流程称为“云端模型工厂”。目前,这个“云端工厂”拥有10 EFLOPS的算力,集群运行效率常年保持在90%以上,全链路迭代周期可达平均5天一次。如此算力规模和运营效率,对标的是头部AI企业。
“比起大语言模型,自动驾驶基座模型的研发更复杂、更有挑战”,刘博士表示自动驾驶模型的训练数据远不止单模态的文本数据,还包括摄像头信息、导航信息等关于物理世界的多模态数据。它要求模型形成对物理世界的认知,并在现实的驾驶场景中,借助自己对世界的认知,完成推理思考、控车决策。对自动驾驶来说,所有技术问题都要从头验证,比如前文提到的规模法则。
在大模型时代,想成为一流的自动驾驶公司,首先必须成为一流的AI公司。在大会现场,小鹏汽车首次展示了两个核心数据:小鹏云上基模训练过程中,处理了超过 40万小时的视频数据;流式多处理器的利用率(streaming multiprocessor utilization,即SM utilization)达到 85%。前者代表云端数据处理能力,后者所提及的“流式多处理器”是 GPU 的核心计算单元。SM利用率是评判GPU计算资源使用效率的重要指标。
此外,他还从云端模型训练和车端模型部署两个层面,拆解了小鹏汽车自动驾驶团队提升世界基座模型训练效率的方法。在模型训练层面,小鹏的研发团队在CPU、GPU等方面做了联合优化,“VLM、VLA等多模态模型不同于LLM,训练过程不只受限于计算瓶颈,还受到数据加载瓶颈、通信瓶颈的限制,大规模并行训练首先要解决这些问题。”
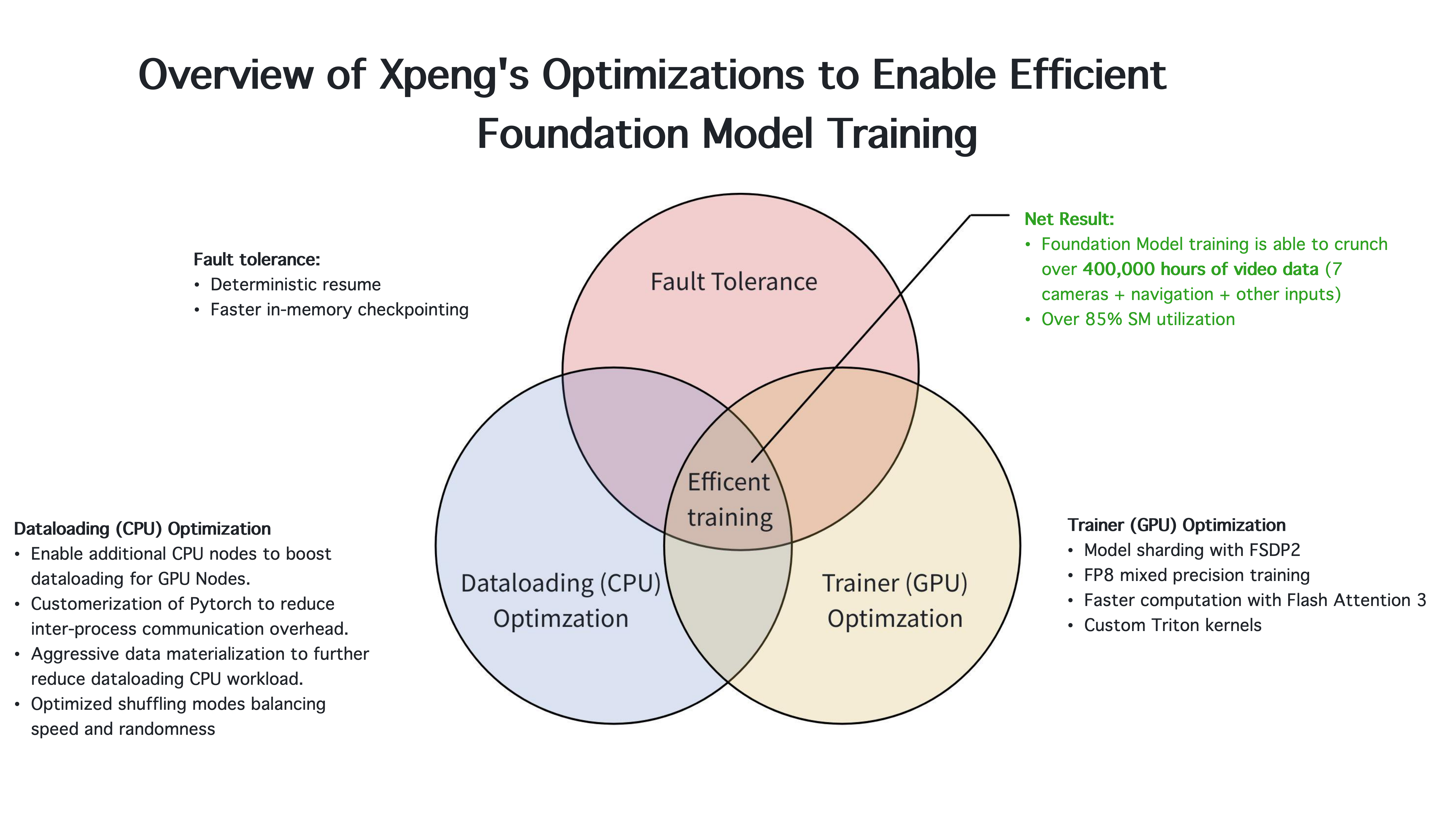
针对数据加载问题,研发团队对CPU的利用做了如下优化:
l 启用额外的CPU节点,以提升GPU节点的数据加载能力
l 对 PyTorch 进行定制化改造,降低进程间通信开销
l 采用激进的数据物化策略,进一步减轻 CPU 在数据加载上的负载
l 优化打乱(shuffling)模式,在速度与随机性之间取得平衡
针对GPU计算资源的利用,研发团队做了以下动作:
l 使用 FSDP 2 实现模型分片
l 使用 FP8 混合精度训练
l 利用 Flash Attention 3 加快计算速度
l 自定义Triton 内核
在车端模型部署层面,小鹏汽车有一个与众不同的优势:自研的图灵AI芯片专为AI大模型而定制,模型、编译器、芯片团队针对下一代模型开展了充分的联合研发工作,比如定制 AI 编译器以最大化执行效率,协同设计硬件友好、量化友好的模型架构,确保软硬件充分耦合,最终“榨干”车端算力。
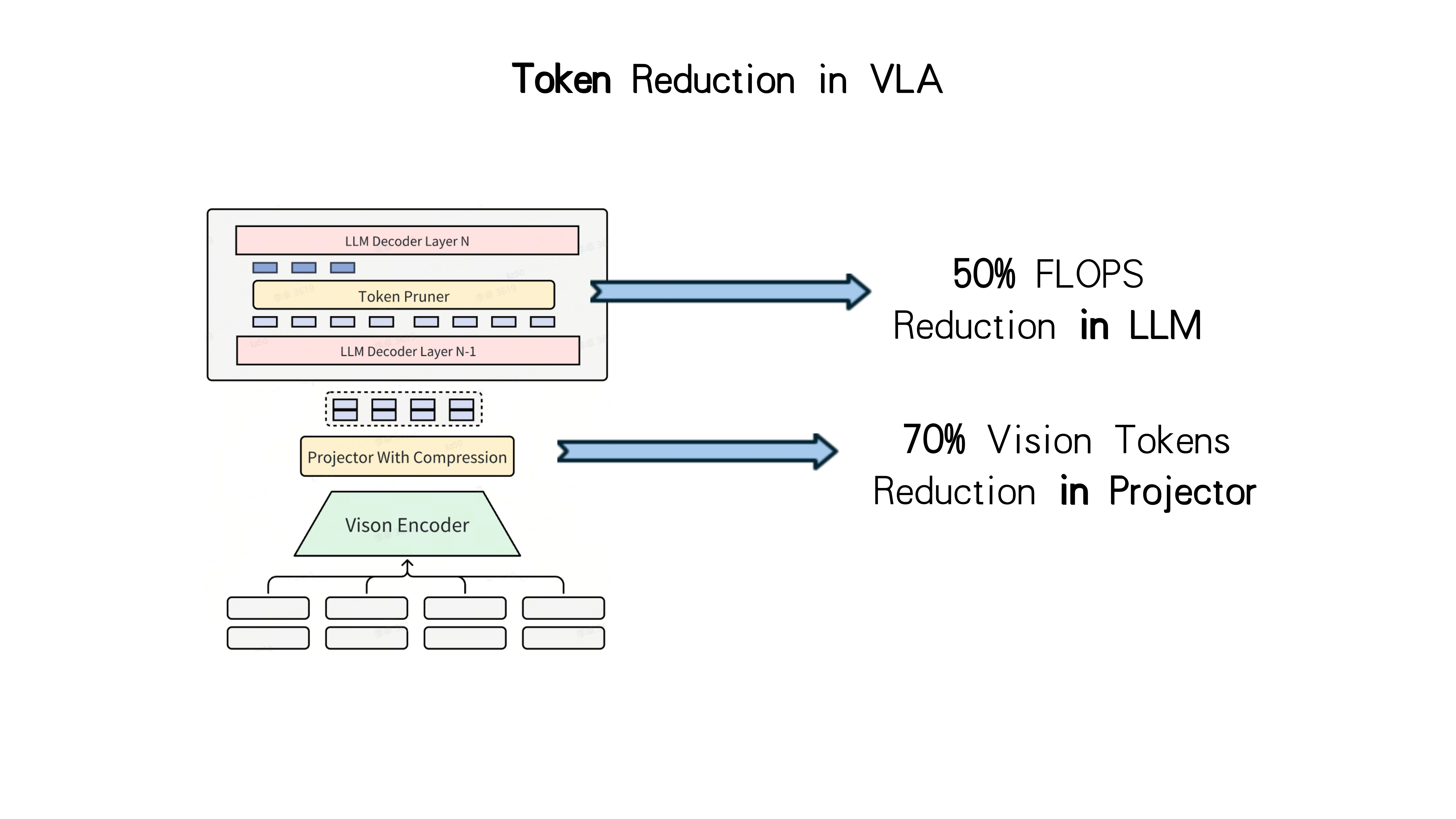
“车端计算量的重要来源是输入的 Token (词元)数量。以配备了 7 个摄像头的 VLA 模型为例,每输入约 2 秒视频内容,会产生超过 5000 个Token。我们一方面要压缩输入中的冗余信息,降低计算延迟。另一方面还要确保输入视频的长度,以获得更丰富的上下文信息。”刘博士称,小鹏团队创新设计了针对VLA模型的 token 压缩方法,可在不影响上下文长度的情况下,将车端芯片的token处理量压缩70%,比如将5000Token压缩到1500Token。”
回到小鹏汽车此次在CVPR WAD分享本身,作为唯一受邀演讲的中国车企,以技术创新为源动力的小鹏汽车将经过几十万用户验证的自动驾驶实践成果反哺学术界,以“商业-科研”的良性循环,为全球自动驾驶研究注入了宝贵的动力。
关于小鹏汽车
小鹏汽车致力于通过探索科技,引领未来出行变革,做“未来出行探索者”。公司总部位于广州,在北京、上海、深圳、肇庆、扬州等地设有研发中心,并在肇庆和广州布局智能制造基地。同时,小鹏汽车面向全球进行研发和销售布局,已在美国设立研发中心、在欧洲多地设立分公司。小鹏汽车坚持全栈自主研发智能辅助驾驶软件和开发核心硬件,为用户带来卓越的智能驾乘体验。2020年8月27日,小鹏汽车正式登陆纽交所,募资规模打破当时全球新能源汽车行业IPO纪录,股票代码为“NYSE:XPEV”;2021年7月7日,小鹏汽车挂牌香港联交所,股票代码“9868.HK”,成为首个在中国香港和美国纽约两地双重主要上市的中国造车新势力。
更多信息,欢迎登陆小鹏汽车官方网站www.xiaopeng.com









{kind=link}